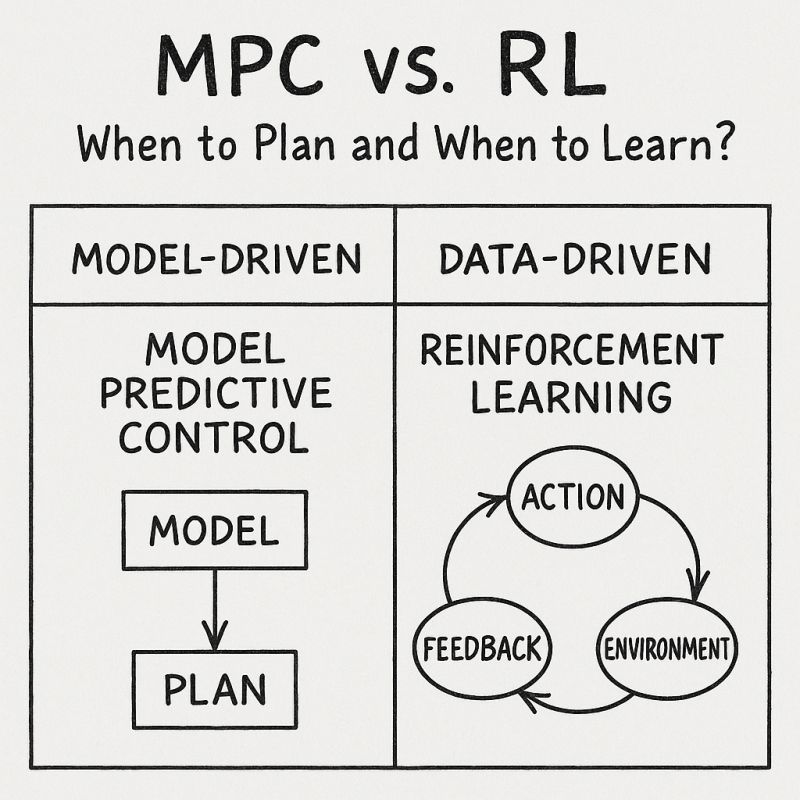
# 🚗 比较 MPC 与 强化学习:以小车到目标点为例本例以一个简单的小车控制任务,展示 MPC(Model Predictive Control) 与 强化学习(Reinforcement Learning) 的形式对比与数学关系
我们考虑一维小车的位置控制问题。状态为 x t x_t x t u t u_t u t x 0 x_0 x 0 x goal x_{\text{goal}} x goal
# 系统动力学模型(离散时间)x t + 1 = f ( x t , u t ) = x t + u t ⋅ Δ t x_{t+1} = f(x_t, u_t) = x_t + u_t \cdot \Delta t x t + 1 = f ( x t , u t ) = x t + u t ⋅ Δ t
# 代价函数(Cost Function)c ( x t , u t ) = ( x t − x goal ) 2 + λ u t 2 c(x_t, u_t) = (x_t - x_{\text{goal}})^2 + \lambda u_t^2 c ( x t , u t ) = ( x t − x goal ) 2 + λ u t 2
控制目标:寻找一系列控制量 { u 0 , u 1 , … } \{u_0, u_1, \dots\} { u 0 , u 1 , … }
对于 MPC 而言,每一时刻都解一个有限时域优化问题:
当前时刻为 t t t H H H
min u t : t + H − 1 ∑ k = 0 H − 1 [ ( x t + k − x goal ) 2 + λ u t + k 2 ] \min_{u_{t:t+H-1}} \sum_{k=0}^{H-1} \left[(x_{t+k} - x_{\text{goal}})^2 + \lambda u_{t+k}^2\right] u t : t + H − 1 min k = 0 ∑ H − 1 [ ( x t + k − x goal ) 2 + λ u t + k 2 ]
受限于:
x t + k + 1 = x t + k + u t + k ⋅ Δ t x_{t+k+1} = x_{t+k} + u_{t+k} \cdot \Delta t x t + k + 1 = x t + k + u t + k ⋅ Δ t
解出控制序列 { u t ∗ , u t + 1 ∗ , … } \{u_t^*, u_{t+1}^*, \dots\} { u t ∗ , u t + 1 ∗ , … } 仅执行第一个动作 u t ∗ u_t^* u t ∗ 下一步重新优化 # MPC 示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import numpy as npimport matplotlib.pyplot as pltfrom scipy.optimize import minimizedef dynamics (x, u, dt=0.1 ): return x + u * dt def cost (u_seq, x0, x_goal, H, dt, lam=0.1 ): x = x0 total_cost = 0 for i in range (H): u = u_seq[i] total_cost += (x - x_goal)**2 + lam * u**2 x = dynamics(x, u, dt) return total_cost def run_mpc (x0=0.0 , x_goal=10.0 , H=10 , T=50 , lam=0.1 ): traj = [x0] x = x0 for t in range (T): u0 = np.zeros(H) res = minimize(cost, u0, args=(x, x_goal, H, 0.1 , lam), bounds=[(-1 , 1 )]*H) u_opt = res.x[0 ] x = dynamics(x, u_opt) traj.append(x) if abs (x - x_goal) < 0.05 : break return traj mpc_traj = run_mpc() plt.plot(mpc_traj, label="MPC Trajectory" ) plt.axhline(10 , color='gray' , linestyle='--' , label="Goal" ) plt.xlabel("Time Step" ) plt.ylabel("Position" ) plt.legend() plt.title("MPC Control Result" ) plt.show()
# 强化学习(以 Q-Learning 为例)强化学习目标是最大化累计奖励(即最小化总代价)。
将代价函数转化为负的即时奖励:
r ( s t , a t ) = − [ ( x t − x goal ) 2 + λ a t 2 ] r(s_t, a_t) = -[(x_t - x_{\text{goal}})^2 + \lambda a_t^2] r ( s t , a t ) = − [ ( x t − x goal ) 2 + λ a t 2 ]
强化学习的目标是学习一个策略 π ( a ∣ s ) \pi(a \mid s) π ( a ∣ s )
max π E π [ ∑ t = 0 ∞ γ t r ( s t , a t ) ] \max_\pi \mathbb{E}_\pi \left[ \sum_{t=0}^{\infty} \gamma^t r(s_t, a_t) \right] π max E π [ t = 0 ∑ ∞ γ t r ( s t , a t ) ]
等价于最小化 MPC 中的累积代价:
min π E π [ ∑ t = 0 ∞ γ t c ( x t , u t ) ] \min_\pi \mathbb{E}_\pi \left[ \sum_{t=0}^{\infty} \gamma^t c(x_t, u_t) \right] π min E π [ t = 0 ∑ ∞ γ t c ( x t , u t ) ]
# Q-Learning 原理推导Q-learning 是一种无模型的强化学习算法,通过学习一个状态 - 动作值函数 Q ( s , a ) Q(s, a) Q ( s , a ) s s s a a a
# Bellman 方程定义:Q ( s t , a t ) = r ( s t , a t ) + γ max a ′ Q ( s t + 1 , a ′ ) Q(s_t, a_t) = r(s_t, a_t) + \gamma \max_{a'} Q(s_{t+1}, a') Q ( s t , a t ) = r ( s t , a t ) + γ a ′ max Q ( s t + 1 , a ′ )
即:当前的 Q 值应等于当前奖励 + 未来最大奖励的折扣。
# Q-learning 更新公式:在交互过程中迭代更新:
Q ( s t , a t ) ← Q ( s t , a t ) + α [ r ( s t , a t ) + γ max a ′ Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ] Q(s_t, a_t) \leftarrow Q(s_t, a_t) + \alpha \left[ r(s_t, a_t) + \gamma \max_{a'} Q(s_{t+1}, a') - Q(s_t, a_t) \right] Q ( s t , a t ) ← Q ( s t , a t ) + α [ r ( s t , a t ) + γ a ′ max Q ( s t + 1 , a ′ ) − Q ( s t , a t ) ]
α \alpha α γ \gamma γ r ( s t , a t ) r(s_t, a_t) r ( s t , a t ) Q ( s t + 1 , a ′ ) Q(s_{t+1}, a') Q ( s t + 1 , a ′ ) 最终收敛后策略为:
π ( s ) = arg max a Q ( s , a ) \pi(s) = \arg\max_a Q(s, a) π ( s ) = arg a max Q ( s , a )
# Q-learning Python 的简化实现# 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import numpy as npimport matplotlib.pyplot as pltx_goal = 10 states = np.arange(0 , 21 ) actions = np.array([-1.0 , 0.0 , 1.0 ]) Q = np.zeros((len (states), len (actions))) def reward (x, u, lam=0.1 ): return -((x - x_goal)**2 + lam * u**2 ) alpha = 0.1 gamma = 0.95 eps = 0.2 for episode in range (500 ): x = 0 for t in range (50 ): s = int (round (x)) a_idx = np.random.randint(len (actions)) if np.random.rand() < eps else np.argmax(Q[s]) u = actions[a_idx] x_next = max (0 , min (20 , x + u * 0.1 )) s_next = int (round (x_next)) r = reward(x, u) Q[s, a_idx] += alpha * (r + gamma * np.max (Q[s_next]) - Q[s, a_idx]) x = x_next if abs (x - x_goal) < 0.5 : break x = 0 traj = [x] for t in range (50 ): s = int (round (x)) a_idx = np.argmax(Q[s]) u = actions[a_idx] x = x + u * 0.1 traj.append(x) if abs (x - x_goal) < 0.05 : break plt.plot(traj, label="Q-Learning Trajectory" ) plt.axhline(10 , color='gray' , linestyle='--' , label="Goal" ) plt.xlabel("Time Step" ) plt.ylabel("Position" ) plt.legend() plt.title("Q-Learning Control Result" ) plt.show()
MPC RL 本质 利用模型进行短期未来预测和优化 通过与环境交互学习长期策略 控制方式 每步优化未来 H H H 学习状态 - 动作策略 π ( a , s ) \pi(a,s) π ( a , s ) Q ( s , a ) Q(s,a) Q ( s , a ) 是否用模型 必须有模型(f ( x t , u t ) f(x_t, u_t) f ( x t , u t ) 可不需要模型(Model-Free) / 可选用模型(Model-Based) 优化目标 最小化代价总和 ∑ c ( x t , u t ) \sum c(x_t, u_t) ∑ c ( x t , u t ) 最大化回报 E π [ ∑ γ t r t ] \mathbb{E}_\pi [\sum \gamma^t r_t] E π [ ∑ γ t r t ] 执行效率 需要在线解优化问题,计算量大 执行时只需查表或网络推理,快速